
Recursive call (ユーザ定義関数の再帰呼出し) ができます。
再帰呼出し?
ユーザ定義関数の内部でもう一度自分自身を呼び出す関数処理をしたい場合があります。この処理を再帰( Recursive )と言います。
例えば TEST_A(); というユーザ定義関数があったとして、この関数 TEST_A(); を TEST_A();の内部でもう一度呼び出すのが再帰処理 ( Recursive Call )です。
TEST_A();→TEST_A();→TEST_A();→TEST_A();→これが延々続く
?それ無限ループになるんじゃね?
イメージとしては無限ループですが、実際「出口」を作らなければただの無限ループになるのが再帰処理です。
「再帰」には明示的な終了条件が必要で、終了条件を満たした時にループから脱出するための「出口」が必要となります。
しかしリソースは有限なので、実際には無限ではなくスタックオーバーフローします。
関数は呼び出しがあるとスタック領域に局所変数や引数やリターンアドレスなどを確保するのですが、関数の内部で関数を呼び出すことでスタック領域を浪費します。スタック領域は無限ではないため、スタックに情報が溜まり過ぎた時点でスタックオーバーフローとなります。スタックオーバーフローは「関数の呼び出しが多すぎるからお前は死ね、お前が死なないのなら俺が死ぬ、死んだ」、こんな意味です。
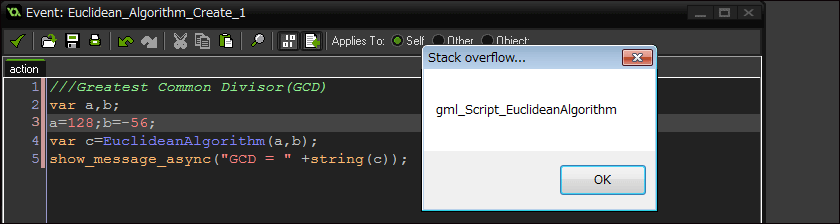
数学的には明快な表現ができるけれど、人間の頭はなかなかついていけないし、再帰を使わなくても非再帰解が存在する場合は、コンピュータの場合は少し手間をかけて非再帰解を用いれば処理速度も速くスタック領域もあまり喰いません。
しかしそれでもプログラム的に再帰が重宝される理由は、再帰に向いているルーチン処理というものがあって、複雑なアルゴリズムでも簡単に表現できる場合があるから再帰を用いるのです。
再帰を利用した初歩的なコードではユークリッドの互除法とかフィボナッチが有名です。これらはどちらも非再帰解が存在しますが、再帰を使ったほうがシンプルに書けます。
参考(IT Pro):シミュレーションと再帰
参考(Tiny Basic for Windows):再帰的アルゴリズム