
進捗 メッセージシステム編 Rev2 #02

データを CSV へパースする機能を Python で実装
ライブラリが強化された現代の Python はすごく強力な言語へと成長を果たした。シンプルな処理をシンプルに書ける言語としての体裁は変わらず。
じゃあ書くよ
というわけで Python を使ってデータを CSV へパースする処理を書き始めたんだ。
できたよ
速かった。
GML で無理やりやろうとしなくて良かった。作業効率が全然違う。
突貫すると作業内容を後で全部忘れるためメモとして仕様などをまとめておく。
仕様とか utf-8
テキストファイルは utf-8 で保存されたものを対象としていて、出力結果も utf-8 で得られる。
BOM の有り、無し
やっかいなのが utf-8 というものが Windows と Mac/Linux で標準がちょっと違う。それが BOM の有り無し。
BOM = byte order mark ( バイトオーダーマーク )
テキストファイルのヘッダーに付与される 3 byte のデータ 0xEF 0xBB 0xBF のこと。
BOM を読み取って活かしているのは Windows のアプリが主で、お得意の拡張子で済ませてよ思うのです、しかしそうもいかないらしい。
utf-8 の BOM 有り/無しはヘッダー情報以外に違いは無く、ヘッダー削れば全く同じ内容のデータになります。
しかし改行扱いにも OS による差異があって、Windows は\r\nで Mac/Linux では\n。
???
とりあえず動くものを作らなくちゃなので、両対応は考えないことにしました。テキストファイルは Windows PC の仕様に沿って utf-8 の BOM 付きを読み取って、出力は…どっちでもいいや。
改行も Windows PC の仕様に沿って、とりあえず Windows PC でテキストは作られたもの!という前提でコードを Ubuntu 上で書き始めます。Debug にコンソール使うから Windows では作業が面倒くさいのです、よっと。
作業は ubuntu 上で行った
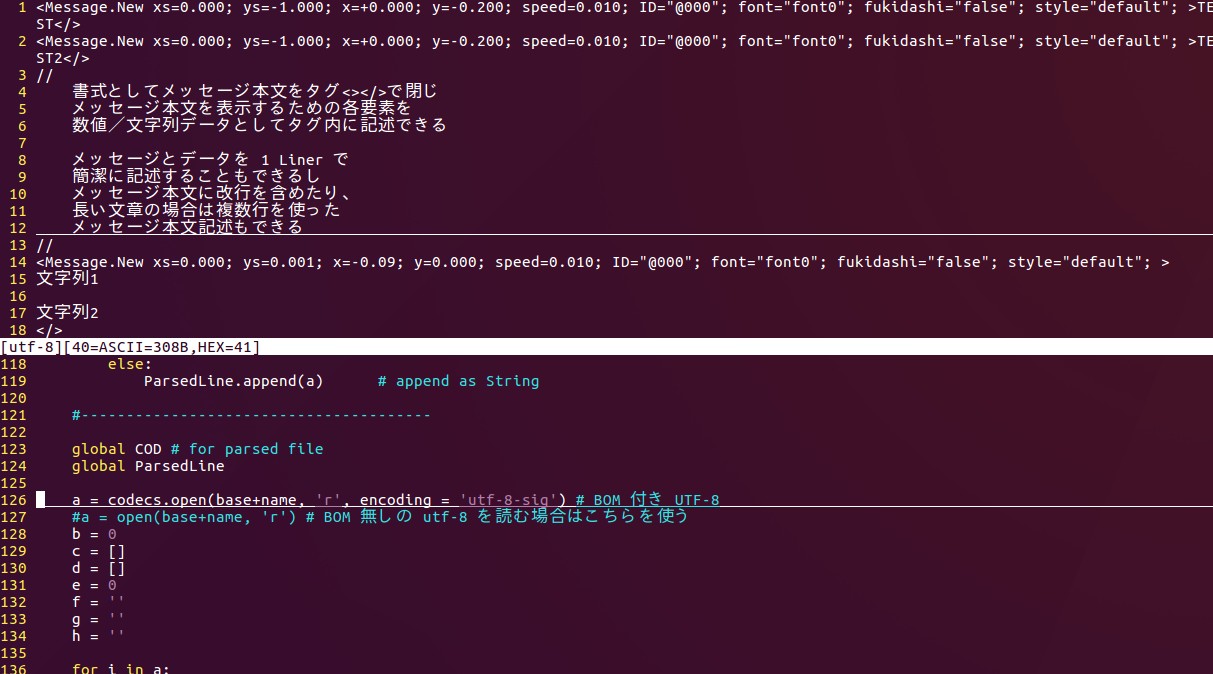
上部が CSV に変換する前のタグ付きソースデータ。変換前ソースとにらめっこしながら CSV へ変換する処理を考えて Python で記述するというミッションです。
下部が vim 上で編集作業中の Python Script 。まずファイルの読み込みで互換性の壁に当たっています。
仕様とか Python のグローバル変数
Python はグローバル変数が基本、ローカル( スコープが限定的な自動変数 ) は関数内定義での標準となる。だからローカル変数を使いたい場合は自作した関数内で変数宣言して、グローバル変数の利用はなるべく限定的となるよう関数の外では使い捨て用途で変な名前の変数を利用しないよう気をつける。
b = 0
c = []
d = []
e = 0変な変数名の代表格としてこういうの。気をつけないとこれが全部グローバル。同名になってもローカルとグローバルは区別されるから安全ではあるけど…。
マークアップの仕様
CSV に変換する前のソースコードは HTML のタグ/マークアップに似せた書式になっています。
開始・終了タグでメッセージ本文( HTML で言うところのコンテンツ ) を囲って、開始タグ内に書式データとして属性値( Attribute ) を記述する形式。
属性値はヘッダーを除いて数値と文字列を含み、厳密に順番が決まっているため必ず数値が先にまとめて記述されます。
数値を先にまとめて書き次に文字列データを置く。これはデバッグが容易となるよう仕様として定められたもので厳守します。
文字列と数値を区別するため文字列データを引用符“で囲むことを義務化。
各Attribute 間を区別するデリミタとしてホワイトスペース が必須、データ終端に;( セミコロン )
を置くことを推奨しているのは可読性のため。
<!-- サンプル 開始タグの書き方 -->
<A.Sample x=+0.1; y=-1.0; ID="テスト"; font="Font0"; >
<!-- 閉じ括弧の前にもホワイトスペースが必須 -->ダメな記述例を以下に
<!-- やってはいけない例、文字列データが数値より先 -->
<A.Sample ID="テスト"; font="Font0"; x=0.1; y=0.1;>
<!-- 閉じ括弧の前にホワイトスペースが無い -->閉じ括弧の前にホワイトスペースが必ず必要な仕様は糞だと思うし実際よく忘れるけど、我慢して使う、そんな心意気で。
<!-- やってはいけない例、デリミタがコロン -->
<!-- デリミタ用途以外のホワイトスペース挿入 -->
<!-- 一貫性の無い/可読性を落とす書き方は禁止 -->
<A.Sample ID ="テスト",font ="Font0",x =0.1,y =0.1 >コロンはドットと見間違えるのでデリミタには使用しません。
ID=とかfont=など Attribute 名の部分は CSV へパースされる時に全て削除されます。これらはデータの意味を説明するコメント文としての働きになっています。デリミタとしてのホワイトスペースなので、無駄なホワイトスペースの挿入は CSV へのパース時に不要なデータが挿入される原因となります。
<!-- セミコロンは可読性のために推奨、エラーは出ない -->
<A.Sample x=+0.1 y=-1.0 ID="テスト" font="Font0" >開始タグ部分の記述は自由度が少なく書式も厳密、唯一の自由はセミコロンの設置有無です。省略してもエラーは出ません。
数値の+-符号も必要なときだけ記述すれば良いからプラスの時は不要。
マークアップ/行単位の処理
「開始タグと終了タグで囲われたコンテンツ」という基本形が守られていれば複数行に跨ってコンテンツが記述されても大丈夫です。改行も検出して GML の仕様に沿った形へ変換されます。インデントとして用いられた場合のタブスペースなど文中スペースは除去されます。
重要なのはやはり開始タグ、開始タグは一行にまとめて書く。
開始タグを複数行に跨いで記述されたケースは想定されていませんのでパースエラーとなります。
<!-- 複数行に跨ったコンテンツの記述をサポート -->
<A.Sample x=+0.1 y=-1.0 ID="テスト" font="Font0" >
制御文字は GML 向けに変換され
インデントなどタブスペースは
除去されます
開始タグに記述される Attribute は
数値と文字列で構成され
数値がかならず先にまとめて記述される
CSV へ変換される時
数値データと文字列データの敷居として
"|" というデータが挿入される
コンテンツ本文には
<></>\;:
のような記号も含めて記述できる
改行コードの挿入は不要かつ
パース時に検出できない
(\r\n)など
複数行に跨る場合、コンテンツの行末に
</> は禁止、閉じる場合は改行して
次の行で </> のみ記述する。
</>可読性を良くするためのインデントが挿入可能。ホワイトスペースは CSV へ変換される際にすべて自動的に除去される対象となっていますが、文中に挿入されたホワイトスペースは除去の対象から外れているため利用可能。
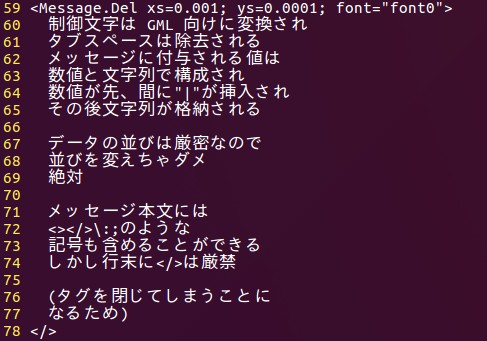
変換前のソースコード
上記例文の変換結果が以下、長文を出力する際に特に威力を発揮。
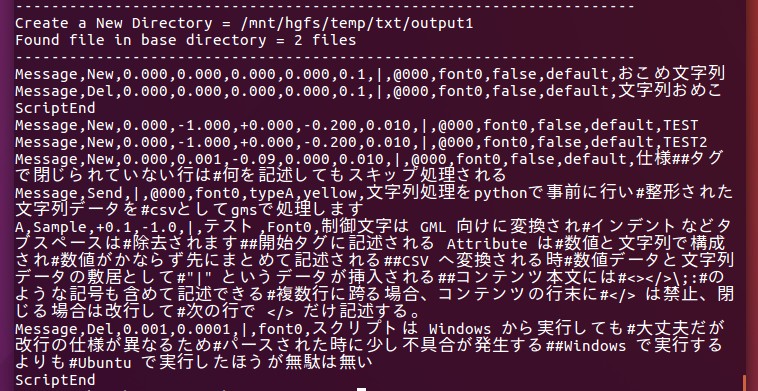
変換結果/コンソールによるデバグ画面
つまりエディタで今書いてる内容がエディタ上での見た目そのまま GMS/GML でも出力できちゃうというスクリプト。
少し手を入れれば GML のスクリプトソースと直接合成して一つの関数かオブジェクト用コードに変換もできるだろう。
入出力に関する仕様
ソースファイルの格納されている指定フォルダからテキストファイルを全て見つけて、全てを変換対象として一括処理します。
CSV に変換して保存するファイルは名前の重複が無いか事前にチェックした上で、連番が割り振られたフォルダへ保存される。前回の変換結果が上書きされずすべて残せる。
今後の課題など
突貫作業故に、完成度としてはまだ拙い。スクリプトの完成度は今後上げる必要があるし検証も不十分。( これで行けるだろ的な手応えは感じている )
変換用に用意した例文が大変少ない現状、今後例文が追加されるごとにスクリプト内で処理や対応を追加する必要が出てくる、かも。
開始タグ内のデータ書式は特に自由度少ないが、記述の自由度よりも「可読性」を重視。
次へ
前へ